
Introduction
AI is capable of table detection in documents.
As the world becomes increasingly digitized, we are all feeling the benefit of having our documentation available online. Whether we are individual consumers, or big businesses, these advantages are palpable. Benefits include:
- It is easy to search for the data you need amongst the data you don’t
- It is easy to compare data across multiple sources
- Storage of digital data (memory) is very cheap these days
- The prevalence of cloud computing means that data sharing is easy and secure
- Digital data is virtually indestructible
- No need for large filing cabinets or additional real estate for storage
As we have seen in previous posts, Deep Data Insight have worked on numerous projects where the introduction of Artificial Intelligence into workflows has brought enormous efficiencies.
However, whilst this process is relatively straightforward for text, it is much harder when it comes to tabulated information. Recently though DDI have pioneered the art of table detection in documents.
Table detection in documents: The Challenge
For centuries, humans have used tables as a way of comparing data and analysing for trends. This evolved in the 20th century when programmers introduced the world’s first spreadsheets. Having data represented in table format means that it can be understood relatively intuitively, and can be the basis for in-depth interrogation with, for example, graphical and figurative interpretations.
The 21st Century has seen enormous advances in the use of Artificial Intelligence and machine learning to understand and predict text. The two main technologies are ICR (Intelligent Character Recognition) and OCR (Optical Character Recognition). ICR and OCR enable a computer to digitise information accurately and quickly.
PDFs are the pre-eminent solution to presenting documents such as invoices and receipts. Electronic Source PDFs will be digitised from the outset; these are also known as ‘Native’ PDFs. ‘Scanned’ PDFs will have started life as a physical document, captured by a mobile device.
The issue arises however when tabulated information is included in documents such as PDFs. This is because the information is no longer being represented in a way that AI can be programmed to understand, and table structure will vary tremendously from one table to another.
This is becoming more of a pronounced challenge as we become increasingly reliant on our own mobile devices. We use their cameras to capture information, and increasingly to convert these images into usable data.
However, because tables by their nature are problematic to AI, table detection in documents has long been a real challenge, and many non-tech industries will still rely on manual processes for extracting and recreating tables in their documents. This is labor intensive and therefore costly and prone to error.
This is largely a sector-agnostic challenge. It follows though that where an increased number of tables are included into the mix of information to be used, then the issue will be more prevalent. Such sectors include engineering, science and academia, FMCG and others.
Table detection in documents: The Solution
Deep Data Insight have created a set of smart solutions using Artificial Intelligence for table detection and data extraction from any type of document. This means that the process of digitising and therefore streamlining workflows need not be held up if the data involved includes tabulated information.
Key to these solutions are two open source technologies to which DDI connects through APIs: Tensorflow and Keras
Tensorflow is an open-source software library that has been created as a learning and development resource for programmers, specifically those involved in machine learning and artificial intelligence.
Keras is another open-source resource which provides a python interface for artificially created neural networks.
By using Tensorflow and Keras, Deep Data Insight can accelerate model building and the creation of scalable machine learning solutions.
As well as these two back-end technologies, DDI employ their significant expertise with a deep learning model known as CNN – Convolutional Neural Network – to analyse the visual imagery.
A novel CNN model developed with pre-trained VGG-19 features
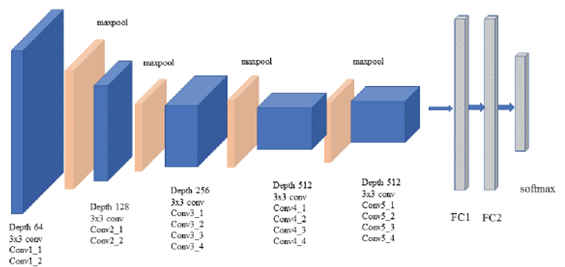
Optical Character Recognition (OCR) is used in order to extract table data accurately. DDI have years of experience with OCR, as this technology underpins its successful EDDIE product.
Table detection in documents: The Results
The first thing to understand is that the huge generic advantages of digitising data are already being gained by Deep Data Insight customers. They are experiencing enormous cost savings across their multiple workflows.
However, since DDI now also has a set of solutions for table detection in documents, and their extraction from varying and multiple documents, these savings be further increased and provided by a single supplier – DDI.
These benefits are sector agnostic, and can be as follows:
- Time saving
- Associated savings from reduced labor
- Reduction in mistakes due to high accuracy of extraction
- Multiple table types can be detected, including:
- Tables with borders, with columns and/or rows
- Tables with borders, but without columns and/or rows
- Borderless tables
- Multi-format tabular data extraction including Excel, CSV and JSON formats
DDI is now supporting its clients across many sectors that are heavily reliant on tabulated information. Insurance, where individual documents needs processing; Construction, where agreement documents often contain tables and in healthcare, where tables are often found in medical prescriptions.
Next Steps
As with any type of technology, table detection in documents is already evolving quickly, and Deep Data Insight are at the forefront of this evolution.
In the not-too distant future, we will see this technology being applied to any object detection problem such as video surveillance and anomaly detection in healthcare.
Notes
Document AI is a Deep Data Insight product developed over years by our data scientists and using the latest deep learning and OCR technologies. For more information about our client successes, read our case studies here https://www.deepdatainsight.com/case-studies/