")
Building a scalable data pipeline does not mean designing the most complex system possible. The best approach is to create a pipeline that reliably moves, transforms, and serves data at your current scale while leaving room to grow. In practice, that means choosing simple components, reducing unnecessary dependencies, and solving real bottlenecks only when they appear.
Many teams overcomplicate data pipeline architecture too early. They adopt too many tools, introduce premature abstractions, and create operational overhead before they have proven demand. A better strategy is to start with a clear use case, define the minimum system that supports it, and expand deliberately.
This guide explains what is a data pipeline, how to design one for scale, and how to avoid the traps that lead to fragile, expensive systems.
Scalable Data Pipeline (Quick Summary)
- Start with business use case, not tools
- Prefer batch over streaming initially
- Keep architecture simple and modular
- Store raw data before transformation
- Add monitoring and data quality early
- Scale only when bottlenecks appear
What Is a Data Pipeline?
A data pipeline is a system that collects, processes, and delivers data from sources to destinations where it can be analyzed or used in applications.
At a basic level, data pipelines connect sources such as applications, databases, APIs, or event streams to storage layers, transformation logic, and downstream tools. This can include batch jobs, streaming systems, validation checks, orchestration, and monitoring.
If you have ever asked, what is data pipeline or what are data pipelines, the simplest answer is this: they help organizations move raw data into usable data without manual effort.
Why Do Teams Overengineer a Data Pipeline?
Teams overengineer a data pipeline when they optimize for hypothetical future complexity instead of current business needs. This often leads to higher costs, slower delivery, and more maintenance without better outcomes.
Overengineering usually happens for a few reasons:
- Teams expect hypergrowth and design for scale they do not yet have
- Engineers adopt tools because they are popular, not necessary
- Architecture is driven by edge cases instead of core use cases
- Ownership, monitoring, and data quality processes are unclear
- Multiple systems overlap and make troubleshooting harder
A scalable design is not the one with the most moving parts. It is the one that remains understandable, reliable, and easy to adapt.
How Do You Build a Scalable Data Pipeline Without Overengineering It?
To build a scalable data pipeline without overengineering it, start with a narrow business goal, select the simplest architecture that can support it, and improve only where data volume, latency, or reliability demands it. Focus on maintainability before sophistication.
That principle sounds simple, but it affects every architectural decision. Instead of starting with a broad platform vision, work backward from the actual output the business needs. For example, if the immediate goal is daily dashboard reporting, a robust batch pipeline may be more appropriate than a streaming-first design.
Start With the Business Use Case, Not the Tool Stack
The most scalable data pipeline architecture begins with a clear use case. Before choosing tools, define what data you need, where it comes from, how often it must update, and who will use it.
Ask practical questions such as:
- What decisions will this data support?
- Is the pipeline for analytics, product features, machine learning, or internal reporting?
- What latency is actually required?
- How accurate and fresh does the data need to be?
- Who is responsible for maintaining it?
This step reduces wasted complexity. A pipeline for weekly finance reporting should not be designed like a real-time fraud detection system. Matching architecture to the actual need is the first safeguard against unnecessary complexity.
What Are the Core Components of a Scalable Data Pipeline?
A scalable data pipeline usually includes data ingestion, storage, transformation, orchestration, and monitoring. The exact tools vary, but these functional layers remain consistent across most implementations.
Here is a practical breakdown:
1. Data ingestion
Ingestion pulls data from source systems such as databases, APIs, SaaS tools, logs, and event streams. Start with the least complex method that meets the refresh requirement, whether that is batch extraction, change data capture, or event-based streaming.
2. Storage
Storage holds raw and processed data for downstream use. In many data pipeline examples, teams use object storage, a warehouse, or both. Separate raw data from cleaned and modeled data so recovery and reprocessing are easier.
3. Transformation
Transformation standardizes, enriches, filters, aggregates, and models data into usable outputs. Keep business logic visible and documented. Hidden logic spread across scripts, notebooks, and dashboards makes scaling harder.
4. Orchestration
Orchestration schedules and coordinates pipeline steps. This includes dependency management, retries, alerting, and task visibility. Choose orchestration that matches your operational maturity, not the most feature-heavy platform available.
5. Monitoring and quality checks
Monitoring ensures the pipeline runs reliably and catches failures quickly. Add checks for freshness, schema drift, row counts, duplicates, and null rates. A pipeline that scales in volume but not in trust is not truly scalable.
Should You Choose Batch or Streaming for Data Pipelines?
Most teams should start with batch unless real-time delivery is a proven requirement. Batch processing is simpler, cheaper to operate, and easier to debug, which makes it the right choice for many early-stage or mid-scale data pipelines.
Use batch when:
- Data freshness can be measured in hours or days
- Reporting and analytics are the main use cases
- Operational simplicity matters more than low latency
- Engineering resources are limited
Use streaming when:
- Business value depends on near real-time decisions
- Event-level responsiveness is required
- Delayed processing creates meaningful risk or revenue loss
One of the most common mistakes in data pipeline architecture is choosing streaming because it feels more scalable. In reality, it adds operational complexity, state handling, ordering concerns, and monitoring challenges. Start with batch and move toward streaming only when the business case is clear.
How Can You Make Data Pipeline Architecture Scalable From Day One?
You can make data pipeline architecture scalable from day one by designing for clear boundaries, modular components, recoverability, and observability instead of adding excessive tools. Scalability comes more from sound structure than from architectural complexity.
Focus on these design principles:
Keep components loosely coupled
Separate ingestion, storage, transformation, and serving layers. This makes it easier to modify one part of the system without rewriting everything else.
Store raw data before transforming it
Retaining raw data gives you a reliable source of truth. It also makes reprocessing possible when business rules change or bugs are discovered.
Make transformations idempotent
An idempotent process can run multiple times without corrupting outputs. This is essential for retries, backfills, and recovery workflows.
Design for schema changes
Schemas will evolve. Plan for nullable fields, versioned contracts, and validation rules so changes do not silently break downstream systems.
Build observability in early
Track job success, runtime, freshness, and data quality from the start. Observability is easier to add early than after multiple teams depend on the pipeline.
These practices support growth without forcing you into an oversized platform.
What Tools Do You Actually Need to Build a Scalable Data Pipeline?
You only need the tools required to ingest, store, transform, orchestrate, and monitor data reliably for your current use case. The most effective stack is often smaller than expected.
A practical starter stack might include:
- One ingestion method
- One primary storage layer
- One transformation framework
- One orchestration tool
- Basic monitoring and alerting
That is enough for many teams. Problems begin when organizations adopt multiple overlapping tools in each category. More tools can create more failure points, more permissions management, more training needs, and more integration work.
This is where many data pipeline examples become misleading. A mature company’s architecture may reflect years of scaling, acquisitions, and organizational specialization. It is not always the right model for a smaller team building its first scalable system.
How Do You Avoid Overengineering in a Data Pipeline?
To avoid overengineering in a data pipeline, solve today’s validated requirements, document tradeoffs clearly, and leave room for future change without building the future in advance. Simplicity should be a deliberate design choice.
Use these decision filters:
- Does this component solve a current problem or a hypothetical one?
- Can the same outcome be achieved with fewer systems?
- Will the team be able to maintain this six months from now?
- Does the complexity improve reliability, speed, or trust in a measurable way?
- Is there a clear migration path if scale increases later?
When the answer is uncertain, choose the simpler design. Simpler systems are easier to test, explain, and evolve.
A Practical Step-by-Step Approach to Building Data Pipelines
The most effective way to build data pipelines is to move in stages. This reduces risk and helps the architecture grow with demand.
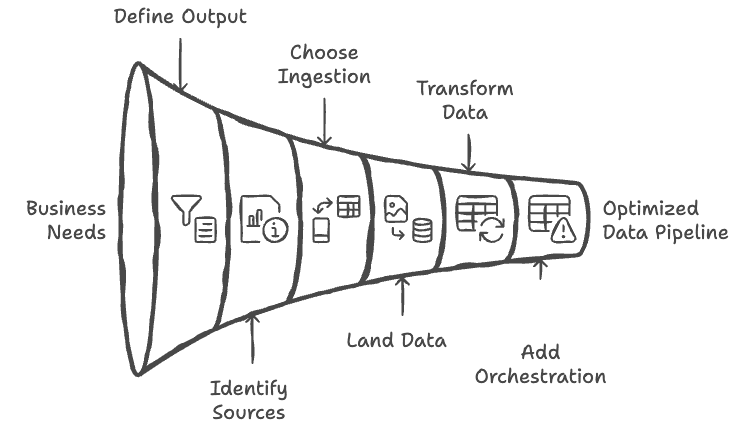
Step 1: Define the output
Start with the business-ready output, such as a dashboard table, API-ready dataset, or model input. This clarifies what the pipeline must produce.
Step 2: Identify the minimum required sources
List only the source systems needed for the first version. Avoid integrating every possible data source upfront.
Step 3: Choose the simplest ingestion pattern
Select batch, scheduled syncs, or event ingestion based on actual latency needs. Do not assume real-time is necessary.
Step 4: Land raw data in reliable storage
Keep an untouched copy of incoming data before applying transformations. This improves recoverability and auditability.
Step 5: Transform data into usable models
Clean, join, validate, and structure the data around the reporting or product need. Keep the logic centralized and documented.
Step 6: Add orchestration and error handling
Schedule dependencies, retries, and notifications so failures are visible and manageable.
Step 7: Monitor, measure, and optimize
Once the pipeline is live, measure runtime, cost, freshness, and failure rates. Scale the system where evidence shows pressure.
This staged method supports data pipeline automation without forcing unnecessary complexity too early.
What Does Good Data Pipeline Automation Look Like?
Good data pipeline automation means the pipeline runs reliably with minimal manual intervention while still remaining transparent and controllable. Automation should reduce repetitive work, not hide critical logic.
Strong automation includes:
- Scheduled or event-triggered runs
- Automatic retries for transient failures
- Alerts for broken jobs or stale data
- Validation checks before publishing outputs
- Clear logs for debugging
- Repeatable backfills and reruns
Automation is valuable when it improves consistency and reduces operational drag. It becomes risky when it obscures ownership or makes failures harder to diagnose.
Data Pipeline Architecture: Simple vs Overengineered
A scalable data pipeline architecture is not the same as an elaborate one. The comparison below shows the difference.
| Approach | Simple Pipeline | Overengineered Pipeline |
| Tools | Minimal | Too many |
| Processing | Batch-first | Streaming-heavy |
| Maintenance | Easy | Complex |
| Scalability | Incremental | Fragile |
For most teams, the simple version creates better long-term scalability.
Typical Errors to Avoid in Data Pipeline Construction
Several recurring mistakes make data pipelines harder to scale than they need to be.
Choosing tools before defining requirements
This leads to architecture shaped by vendor categories rather than real use cases.
Mixing business logic across multiple layers
When rules live partly in ingestion, partly in SQL models, and partly in dashboards, trust and maintainability decline.
Ignoring data quality until later
Bad data quality compounds quickly. Add basic checks early.
Designing only for success paths
Backfills, retries, late-arriving data, and schema changes are normal. Plan for them.
Treating scalability as only a volume problem
Scalability also includes team scalability, operational simplicity, cost control, and ease of change.
Avoiding these issues often matters more than adopting a more advanced stack.
What Are Some Practical Data Pipeline Examples?
Useful data pipeline examples usually share one trait: they are designed around a specific outcome, not abstract technical ambition.
Here are a few examples:
Analytics reporting pipeline
A batch job extracts data from an application database and CRM each night, lands it in storage, transforms it into reporting tables, and serves dashboards to business teams.
Product event pipeline
Application events are captured continuously, stored in raw form, processed into session and behavior models, and used for product analytics or personalization.
Finance reconciliation pipeline
Daily exports from payment systems and accounting platforms are ingested, validated, matched, and loaded into a warehouse for audit-ready reconciliation reports.
In each example, scalability depends on reliability, clarity, and the ability to adapt as demand grows.
How Do You Know When to Scale the Pipeline Further?
You should scale a data pipeline further when current architecture creates measurable pain in reliability, latency, cost, or developer productivity. Scaling should be triggered by evidence, not fear.
Signals include:
- Jobs regularly miss SLAs
- Data volume causes unstable runtimes
- Backfills take too long
- Pipeline failures are hard to diagnose
- Business users do not trust the outputs
- Maintenance work slows new delivery
When these issues appear, improve the specific constraint rather than rebuilding everything. Incremental scaling is usually more effective than platform reinvention.
Conclusion: Build for the Next Stage, Not the Final Stage
The best way to build a scalable data pipeline is to keep it as simple as possible for as long as possible. Start with the use case, choose a practical architecture, automate the repetitive parts, and strengthen the system where real bottlenecks appear.
A strong data pipeline architecture is reliable, observable, and understandable. It supports growth without forcing complexity before it is needed. That is how you scale without overengineering it.
FAQ
What is a data pipeline in simple terms?
A data pipeline is a system that moves data from source systems to a destination where it can be cleaned, transformed, and used. It automates the flow of data so teams can analyze information, power applications, and make decisions more efficiently.
What is the best way to build scalable data pipelines?
The best way to build scalable data pipelines is to start with a clear use case, choose the simplest architecture that meets current needs, and improve specific bottlenecks over time. Scalability comes from good structure, observability, and maintainability rather than unnecessary complexity.
What is the difference between batch and streaming in data pipeline architecture?
In data pipeline architecture, batch processes data on a schedule, while streaming processes data continuously or near real time. Batch is simpler and often sufficient for analytics, while streaming is better for use cases that require immediate action on incoming events.
How does data pipeline automation help?
Data pipeline automation reduces manual work by scheduling ingestion, transformations, quality checks, and alerts. Good automation improves consistency and reliability while making the pipeline easier to operate, monitor, and scale.